Popular Libraries for Machine Learning
Python provides several powerful libraries that simplify the implementation of machine learning algorithms:
scikit-learn
scikit-learn is a comprehensive library for classical machine learning tasks such as classification, regression, clustering, and dimensionality reduction. It is built on NumPy, SciPy, and Matplotlib and provides a simple and efficient API for users. scikit-learn excels in ease of use, scalability, and integration with other libraries.
Key features of scikit-learn include:
- Support for various supervised and unsupervised learning algorithms
- Integration with other Python libraries such as NumPy and Pandas
- Tools for model evaluation, cross-validation, and hyperparameter tuning
- Robust documentation and community support

TensorFlow
TensorFlow is an open-source deep learning framework developed by Google. It is designed for large-scale machine learning tasks and excels in training deep neural networks. TensorFlow offers both high-level APIs (like Keras) for quick model prototyping and low-level APIs for precise control over model architecture and training process. It is widely used in research and production for tasks ranging from natural language processing to image recognition.
Key features of TensorFlow include:
- Support for both CPU and GPU computations
- Distributed computing capabilities for scaling across multiple devices and servers
- TensorBoard for visualization of model graphs and training metrics
- Compatibility with other frameworks like Keras and TensorFlow Serving for deployment

PyTorch
PyTorch is another popular deep learning framework known for its flexibility and ease of use. Developed by Facebook's AI Research lab (FAIR), PyTorch supports dynamic computation graphs, making it well-suited for research and development. It offers strong GPU acceleration support and is favored by researchers for its intuitive interface and Pythonic coding style. PyTorch is commonly used in fields such as computer vision, natural language processing, and reinforcement learning.
Key features of PyTorch include:
- Dynamic computation graphs that enable changes to model architecture during runtime
- Efficient memory usage and support for automatic differentiation
- Integration with popular Python libraries and frameworks
- TorchScript for exporting models to run independently of Python runtime

Keras
Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It focuses on enabling fast experimentation and supports both convolutional networks (CNNs) and recurrent networks (RNNs). Keras provides user-friendly APIs, allowing developers to quickly prototype deep learning models with minimal code. It is widely used for building and training deep learning models, especially in scenarios where rapid iteration and prototyping are crucial.
Key features of Keras include:
- Modularity, simplicity, and ease of use for building complex neural networks
- Compatibility with multiple backends and seamless switching between them
- Built-in support for GPU acceleration and distributed computing
- Extensive documentation, tutorials, and a supportive community

Training and Evaluating Basic Models
Let's dive into some foundational machine learning models using scikit-learn:
Linear Regression
Linear regression is a simple yet powerful model used for predicting continuous values. It establishes a linear relationship between input variables (X) and the output variable (y).
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 4, 9, 16, 25])
model = LinearRegression()
model.fit(X, y)
# Predict
y_pred = model.predict(X)
# Plot
plt.scatter(X, y, color='black')
plt.plot(X, y_pred, color='blue', linewidth=3)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Linear Regression')
plt.show()

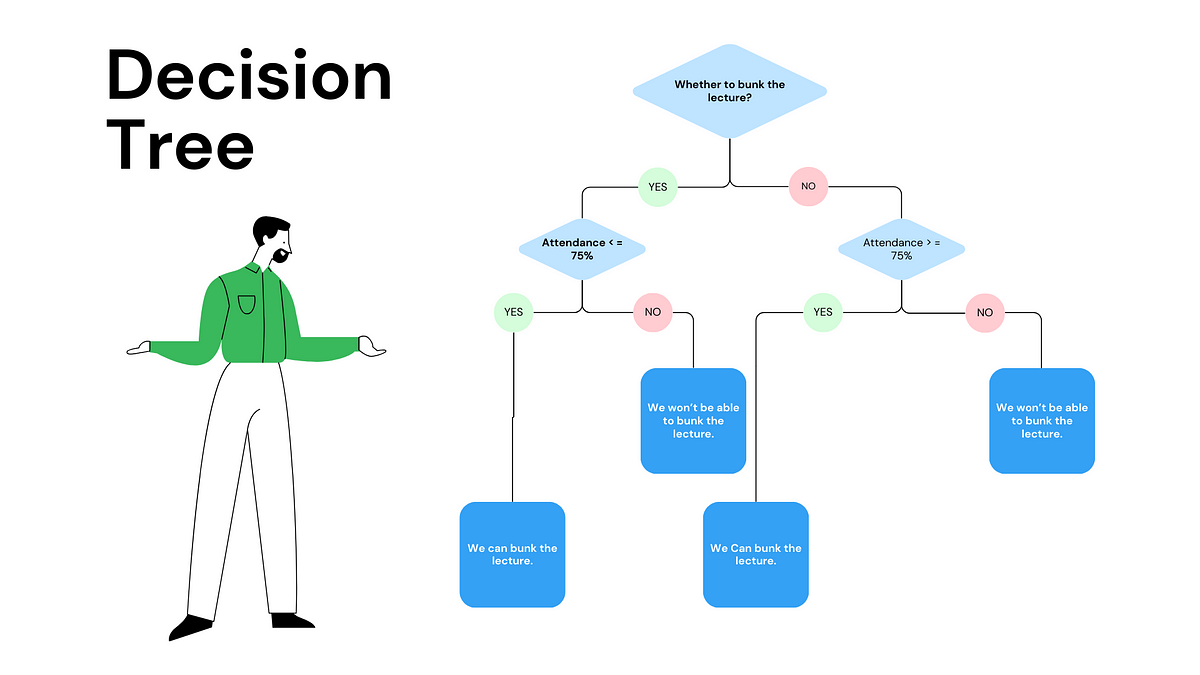
Decision Trees
Decision trees are versatile models capable of handling both classification and regression tasks. They partition the data into subsets based on the features' values to make predictions.
from sklearn.tree import DecisionTreeRegressor
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 4, 9, 16, 25])
model = DecisionTreeRegressor()
model.fit(X, y)
# Predict
y_pred = model.predict(X)
# Plot
plt.scatter(X, y, color='black')
plt.plot(X, y_pred, color='green', linewidth=3)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Decision Tree Regression')
plt.show()
Advanced Machine Learning Models
Explore more advanced machine learning techniques that offer improved performance and flexibility:
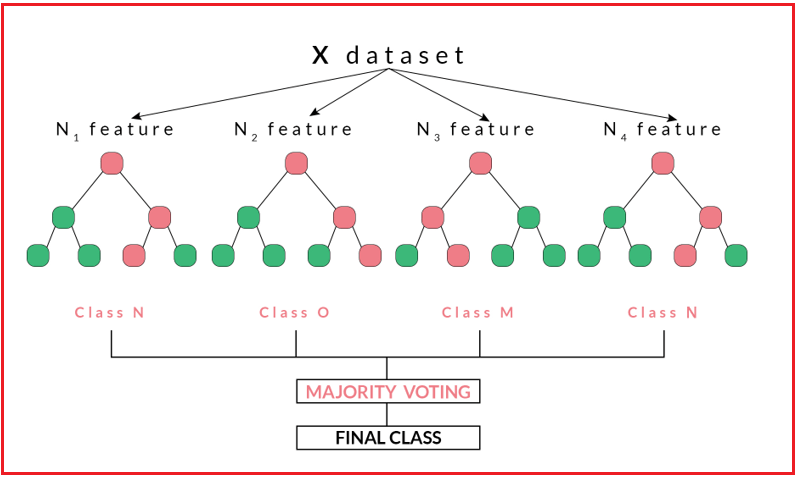
Random Forests
Random Forests are ensemble learning methods that combine multiple decision trees to improve predictive accuracy. They mitigate overfitting and enhance model robustness.
from sklearn.ensemble import RandomForestRegressor
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 4, 9, 16, 25])
model = RandomForestRegressor()
model.fit(X, y)
# Predict
y_pred = model.predict(X)
# Plot
plt.scatter(X, y, color='black')
plt.plot(X, y_pred, color='green', linewidth=3)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Random Forest Regression')
plt.show()
Support Vector Machines (SVM)
Support Vector Machines are powerful supervised learning models used for classification and regression tasks. They work well with complex datasets and can capture intricate relationships.
from sklearn.svm import SVR
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 4, 9, 16, 25])
model = SVR(kernel='linear')
model.fit(X, y)
# Predict
y_pred = model.predict(X)
# Plot
plt.scatter(X, y, color='black')
plt.plot(X, y_pred, color='purple', linewidth=3)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Support Vector Regression')
plt.show()

Model Evaluation and Hyperparameter Tuning
Evaluate model performance and optimize hyperparameters to improve predictive accuracy:
Cross-Validation
Cross-validation assesses how well a model generalizes to independent datasets by splitting the data into multiple subsets and evaluating each one.
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
# Sample data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 4, 9, 16, 25])
model = LinearRegression()
scores = cross_val_score(model, X, y, cv=5)
print("Cross-validated scores:", scores)
print("Mean score:", np.mean(scores))
Grid Search for Hyperparameter Tuning
Grid Search is a technique for systematically working through multiple combinations of hyperparameters to determine the best parameters for a model.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVR
# Sample data
param_grid = {'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']}
grid_search = GridSearchCV(SVR(), param_grid, cv=5)
grid_search.fit(X, y)
print("Best parameters:", grid_search.best_params_)
print("Best estimator:", grid_search.best_estimator_)
Data Preprocessing and Feature Engineering
Prepare your data for machine learning models with preprocessing techniques and feature engineering.
Handling Missing Values
Missing data is a common issue in datasets that can impact model performance. Imputation techniques such as mean or median filling can handle missing values.
from sklearn.impute import SimpleImputer
# Sample data
X = [[1, 2], [3, np.nan], [7, 6]]
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(X)
print(X_imputed)
Feature Scaling
Feature scaling transforms data to a standard scale, improving model performance and convergence. Common techniques include StandardScaler for normalizing data.
from sklearn.preprocessing import StandardScaler
# Sample data
X = [[1, 2], [3, 6], [7, 6]]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print(X_scaled)
Example Project: Predicting House Prices
Apply machine learning techniques to a real-world problem: predicting house prices.
Loading the Dataset
import pandas as pd
# Load dataset
url = 'house-prices.csv'
data = pd.read_csv(url)
print(data.head())
Data Preprocessing
Data preprocessing is crucial for preparing raw data into a format suitable for machine learning models. Steps include handling missing values, encoding categorical variables, and scaling features.
# Handle missing values
data = data.fillna(data.mean())
# Feature encoding
data = pd.get_dummies(data, columns=['categorical_feature'])
# Feature scaling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
features = data.drop('price', axis=1)
target = data['price']
features_scaled = scaler.fit_transform(features)
Training the Model
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Split data
X_train, X_test, y_train, y_test = train_test_split(features_scaled, target, test_size=0.2, random_state=42)
# Train model
model = LinearRegression()
model.fit(X_train, y_train)
# Evaluate model
score = model.score(X_test, y_test)
print(f'Model R^2 score: {score}')